
Filtering, Pagination & Sorting
This is an exciting section of the tutorial where you’ll implement some key features of many robust APIs! The goal is to
allow clients to constrain the list of Link elements returned by the feed query by providing filtering and
pagination parameters.
Let’s jump in! 🚀
Filtering
By using PrismaClient, you’ll be able to implement filtering capabilities to your API without too much effort.
Similarly to the previous chapters, the heavy-lifting of query resolution will be performed by Prisma. All you need to
do is forward incoming queries to it.
The first step is to think about the filters you want to expose through your API. In your case, the feed query in your
API will accept a filter string. The query then should only return the Link elements where the url or the
description contain that filter string.
Next, you need to update the implementation of the feed resolver to account for the new parameter clients can provide.
If no filter string is provided, then the where object will be just an empty object and no filtering conditions will
be applied by Prisma Client when it returns the response for the links query.
In cases where there is a filter carried by the incoming args, you’re constructing a where object that expresses
our two filter conditions from above. This where argument is used by Prisma to filter out those Link elements that
don’t adhere to the specified conditions.
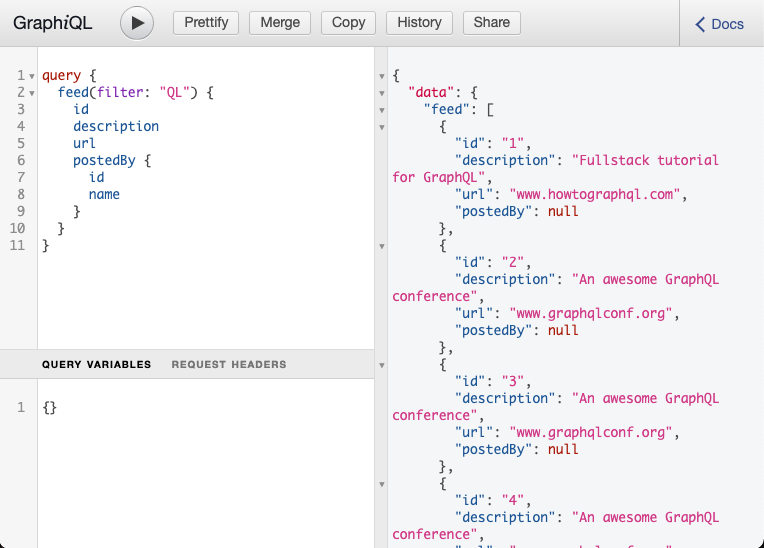
That’s it for the filtering functionality! Go ahead and test your filter API - here’s a sample query you can use:
query {
feed(filter: "QL") {
id
description
url
postedBy {
id
name
}
}
}
Pagination
Pagination is a tricky topic in API design. On a high-level, there are two major approaches for tackling it:
- Limit-Offset: Request a specific chunk of the list by providing the indices of the items to be retrieved (in fact, you’re mostly providing the start index (offset) as well as a count of items to be retrieved (limit)).
- Cursor-based: This pagination model is a bit more advanced. Every element in the list is associated with a unique ID (the cursor). Clients paginating through the list then provide the cursor of the starting element as well as a count of items to be retrieved.
Prisma supports both pagination approaches (read more in the docs). In this tutorial, you’re going to implement limit-offset pagination.
Note: You can read more about the ideas behind both pagination approaches here.
Limit and offset have different names in the Prisma API:
- The limit is called
take, meaning you’re “taking”xelements after a provided start index. - The start index is called
skip, since you’re skipping that many elements in the list before collecting the items to be returned. Ifskipis not provided, it’s0by default. The pagination then always starts from the beginning of the list.
So, go ahead and add the skip and take arguments to the feed query.
Now, adjust the resolver implementation:
Really all that’s changing here is that the invocation of the links query now receives two additional arguments which
might be carried by the incoming args object. Again, Prisma will take care of the rest.
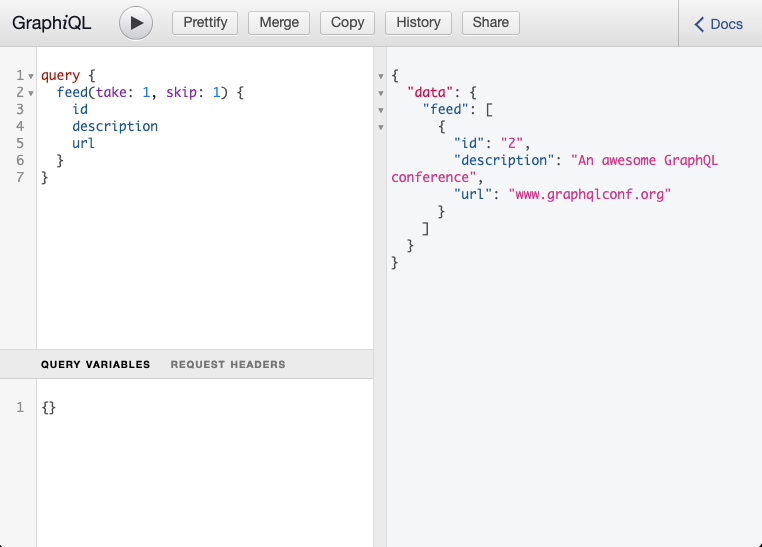
You can test the pagination API with the following query which returns the second Link from the list:
query {
feed(take: 1, skip: 1) {
id
description
url
}
}
Sorting
With Prisma, it is possible to return lists of elements that are sorted (ordered) according to specific criteria. For
example, you can order the list of Links alphabetically by their url or description. For the Hacker News API,
you’ll leave it up to the client to decide how exactly it should be sorted and thus include all the ordering options
from the Prisma API in the API of your GraphQL server. You can do so by creating an
input type and an enum to represent the ordering options.
This represents the various ways that the list of Link elements can be sorted (asc = ascending, desc = descending).
The implementation of the resolver is similar to what you just did with the pagination API.
Awesome! Here’s a query that sorts the returned links by their creation dates:
query {
feed(orderBy: { createdAt: asc }) {
id
description
url
}
}
Returning the total amount of Link elements
The last thing you’re going to implement for your Hacker News API is the information how many Link elements are
currently stored in the database. To do so, you’re going to refactor the feed query a bit and create a new type to be
returned by your API: Feed.
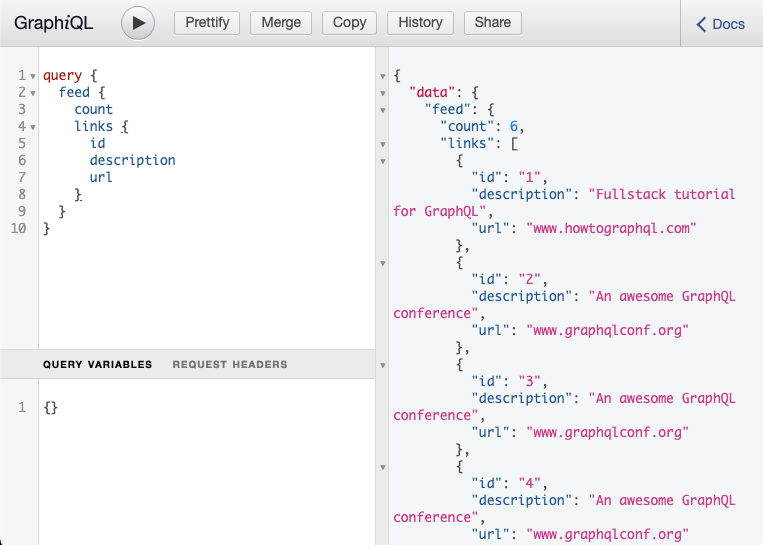
You can now test the revamped feed query as follows:
query {
feed {
count
links {
id
description
url
}
}
}
Unlock the next chapter
What style of pagination comes out of the box in GraphQL
Offset-based pagination
Cursor-based pagination
Key-Set based pagination
None, you implement the style which fits your needs
Skip